[ This is a BACKUP server. Do NOT use unless the primary server is DOWN. ]
Please be familiar with warmup1 FAQ.Quick index:
- Commandline
- Clock resolution and timestamp
- Basic design
- how do I start this assignment?
- no, I mean how do I start this assignment from scratch?
- I'm confused about multithreading, how can I start this assignment?
- are we supposed to use the solution to the producer-consumer problem in Ch 2?
- can we read the entire tsfile first to check for errors before starting simulation?
- Pthread
- Compiling & Linking
- Running the simulation
- what does it "inter-arrival time" really mean?
- if lambda is 10000, what should be the value of packet inter-arrival time?
- if mu is 10000, what should be the value of service time?
- what does it mean when the spec says "blocks"?
- when should the service time of a packet be determined?
- what method is best for thread-to-thread communication?
- how to get around the problem that the output looks messed up?
- I'm locking the mutex when I call print(), how come the timestamps are still out of order?
- is it reasonable to sleep longer than was asked?
- can usleep() return early?
- can I call usleep() to sleep for more than one second?
- what's the difference between usleep() and select()?
- are we supposed to call usleep() when we have the mutex locked?
- my program is not catching <Ctrl+C> every time, what could be the problem?
- does a trace specification file has to have an .txt file name extension?
- can I assume that all the data in a trace specification file are integers?
- how can I know if my code is doing busy-waiting or not?
- how can I print/format a timestamp on each line of trace?
- when I print the "begin service" line, how should I print the amount of service requested?
- does pressing <Ctrl+C> terminate the simulation?
- how come pressing <Ctrl+C> messes up the printout when I use "section-A.csh"?
- Debugging
- Handle Input File
- Measuring things
- Statistics
- what does "average number of packets in a server" mean?
- what does "average number of packets in Q1" mean?
- how do you print a real value with 6 significant digits?
- do we need to include the dropped packets while calculating the averages?
- how can I keep a running average?
- how can I keep a running standard deviation?
./warmup2 -lambda 0.25
and your code has detected that argv[1] contains "-lambda". This
means that you should parse argv[2] for a real value. So, you should make
sure that argc is at least 3 (which means that argv[2] contains a valid string).
Then you make sure that argv[2][0] is not the "-" character.
Then you can "read" a double value from argv[2] by doing:
double dval=(double)0;
if (sscanf(argv[2], "%lf", &dval) != 1) {
/* cannot parse argv[2] to get a double value */
} else {
/* success */
}
This is not perfect, but it's good enough!
By the way, for a real value, use double and never use float!
I would suggest that you should try the simple way to parse commandline options in the Programming FAQ.
The man pages for gettimeofday() shows that the first argument of gettimeofday() is an address of a data structure called "struct timeval". This data structure has two fields, "tv_sec", and "tv_usec", both are 32-bit integers. I would recommend that you use this data structure to keep timestamps and use timersub() to get the difference between such timestamps and use timeradd() to add timestamps. You should also write your own utility functions to do things like converting such a timestamp to a string for printing/displaying and converting such a timestamp to double to be used in calculating statistics. This way, you will never have to worry about round-off errors.
The time returned by gettimeofday() is affected by discontinuous jumps in the system time (e.g., if the system administrator manually changes the system time).I don't know why our 32-bit Ubuntu 16.04 system would "have discontinuous jumps in the system time". The example mentioned above was that a system administrator can manually change the system time. Clearly, the grader will not do that during grading!
The bottomline is that even though it's possible that our clock can go backwards, but in practice, given the test cases in our grading guidelines, this most likely would not cause any problem. But if you are concerned about this issue, instead of calling gettimeofday(), maybe it's best to call my_gettimeofday() below (implemented using clock_gettime() mentioned in the man pages of gettimeofday()).
#include <sys/time.h>
#include <time.h>
int my_gettimeofday(struct timeval *tv, struct timezone *tz)
{
struct timespec ts;
int rc = clock_gettime(CLOCK_REALTIME_COARSE, &ts);
if (rc != 0) return rc;
tv->tv_sec = ts.tv_sec;
tv->tv_usec = (suseconds_t)(ts.tv_nsec / 1000);
return 0;
}
The returned clock value does not look anything like gettimeofday(). If you want the clock value to look more that what's returns by
gettimeofday(), please use the more elaborate implementation below:
#include <sys/time.h>
#include <time.h>
int my_gettimeofday(struct timeval *tv, struct timezone *tz)
{
static int first_time = 1;
static struct timeval time_difference;
struct timespec ts;
if (first_time) {
struct timeval start_time, start_time2;
int debug_print_resolution = 0;
if (debug_print_resolution) {
struct timespec resolution;
clock_getres(CLOCK_MONOTONIC_RAW , &resolution);
printf("%s resolution is %d seconds and %d nanoseconds\n",
"CLOCK_MONOTONIC_RAW",
(int)resolution.tv_sec, (int)resolution.tv_nsec);
}
gettimeofday(&start_time, NULL);
int rc = clock_gettime(CLOCK_MONOTONIC_RAW, &ts);
if (rc != 0) return rc;
start_time2.tv_sec = ts.tv_sec;
start_time2.tv_usec = (suseconds_t)(ts.tv_nsec / 1000);
timersub(&start_time, &start_time2, &time_difference);
first_time = 0;
}
int rc = clock_gettime(CLOCK_MONOTONIC_RAW, &ts);
if (rc != 0) return rc;
struct timeval now;
now.tv_sec = ts.tv_sec;
now.tv_usec = (suseconds_t)(ts.tv_nsec / 1000);
timeradd(&now, &time_difference, tv);
return 0;
}
On a standard 32-bit Ubuntu 16.04 system, it looks like the clock resolution is 4 millsecond for CLOCK_REALTIME_COARSE
and that resolution is too low for this assignment. This is why I used CLOCK_MONOTONIC_RAW (which has a 1 nanosecond resolution).
I have tested my_gettimeofday() on standard 32-bit Ubuntu 16.04 systems and unfortunately, on some machines,
it appears to have the same problem as gettimeofday()!
I don't think there is a need to use my_gettimeofday() and you should stick to using gettimeofday(). You should only use my_gettimeofday() if you are sure that this is the only way to make your program work. Personally, I have never seen a real need to use my_gettimeofday() for this assignment! I have only heard claims (which I cannot verify on my machines) from students that my_gettimeofday() is needed.
Trick To Try
Finally, before you try something extreme like my_gettimeofday() above, try the following trick. I was told that this works (although I cannot verify the claim). Here's a function that doesn't really do anything (except making a time-related system call that returns immediately):
void fake_nanosleep()
{
struct timespec req = { 0, 0 };
nanosleep(&req, NULL);
}
Right before you unlock the mutex, call this function and see if it helps.
The 4 child threads will collaborate to update the shared data structures (Q1, Q2, token count, and anything that's shared by these threads), which is protected by a single mutex (with a single condition variable). In order to gain access (read or write) to any of these data structures, a thread have to lock the mutex, do something to the data structure, and unlock the mutex. If a thread has to wait for anything, you must not do busy-waiting and must have your thread go to sleep.
You can imagine 4 people trying to accomplish the tasks described by the spec and each person must follow the protocol specified in the spec. What does each person/thread have to do to accomplish the tasks so that things will always work according to the spec? The packet arrival person/thread needs to generate packet in the specified way, then create a packet and add it to Q1 (and in some cases, it needs to then remove this packet from Q1 and move it into Q2). If it moves a packet into Q2, it needs to wake up a sleeping server thread (the spec says that you must call pthread_cond_broadcast() and not pthread_cond_signal()). The token depositing person/thread needs to generate tokens in the specified way, then add a token to the token bucket (i.e., just increment the token count), and in some cases, it needs to remove a packet from Q1 and move it into Q2. If it moves a packet into Q2, it needs to wake up a sleeping server thread using pthread_cond_broadcast(). Of course, if you call pthread_cond_broadcast() and both server threads are sleeping in the condition variable queue, both server threads will be woken up (and they will return from pthread_cond_wait()). A server person/thread checks if Q2 is empty or not. If Q2 is empty, it goes to sleep (in a CV queue). If Q2 is not empty, it must remove a packet from Q2, unlock the mutex, and simulate the transmission of the packet by calling usleep() to sleep the service time of the packet.
Please remember that whenever you need to use any of the shared data, you must have the mutex locked. What about when the packet arrival thread sleeps to wait for the right time to generate the next packet or when the token depositing thread sleeps to wait for the right time to generate the next token? Well, you should make sure that they go to sleep with the mutex unlocked. What about when a server thread sleeps to simulate the transmission of the packet? You should also make sure that it goes to sleep with the mutex unlocked.
If any of this sounds unfamiliar to you, please review lectures regarding thread synchronization (Ch 2).
Then set n to 1 (just hard-code it) and modify the first procedure of all your threads to work with n=1 and use the default values for all other simulation parameters. This means that lambda = 1, mu = 0.35, r = 1.5, B = 10, and P = 3 and you should use global variables for all these values. How should your simulation go in this case? Since packet inter-arrival time is one second, packet p1 should arrive soon after 1 second into the simulation. What about the arrival of tokens? Since the token inter-arrival time is 666.667ms, token t1 should arrive before the first packet. Therefore, when p1 arrives, you should create a packet object and append it to Q1. At this point, the packet thread should see that there is not enough token in the token bucket and p1 is left at the head of Q1. The packet arrival thread should self-terminate because all packets have arrived.
When token t2 arrives, the token bucket should then have 2 tokens. But that's not enough to move p1 to Q2. When token t3 arrives, the token bucket should then have 3 tokens and the token thread should remove p1 from Q1 and then append p1 to Q2 and broadcast the CV to wake up all the server threads. The token arrival thread should self-terminate because all packets have arrived and Q1 is empty.
Whichever the server thread that wakes up first should dequeue p1 from Q2 and start transmitting p1 by sleeping for 2857ms. The server thread that wakes up next should self-terminate because all packets have arrived and both Q1 and Q2 are empty. It should also broadcast the CV because it doesn't know what the other server thread is doing. When the server thread that's transmitting p1 wakes up, it should self-terminate and broadcast the CV.
The main thread should return from joining with all these 4 threads and self-terminate. What should be the total simulation time for this case? It should be the time to create 3 tokens plus the service time of a packet. So, your emulation end time should be a little longer than 4.857 seconds. If your emulation end time is less than 4.857 seconds or much longer than 4.857 seconds, you need to figure out if there is a bug in your code.
Below is a sample printout for your reference. Of course, due to the nature of a time-driven simulation, your printout should be slightly different. What's important is that you understand exactly why the sequence of events below is the ONLY correct sequence of events for this set of simulation parameters!
Emulation Parameters:
number to arrive = 1
lambda = 1
mu = 0.35
r = 1.5
B = 10
P = 3
00000000.000ms: emulation begins
00000667.976ms: token t1 arrives, token bucket now has 1 token
00001045.872ms: p1 arrives, needs 3 tokens, inter-arrival time = 1045.872ms
00001046.029ms: p1 enters Q1
00001335.384ms: token t2 arrives, token bucket now has 2 tokens
00002127.836ms: token t3 arrives, token bucket now has 3 tokens
00002128.261ms: p1 leaves Q1, time in Q1 = 1082.232ms, token bucket now has 0 token
00002129.187ms: p1 enters Q2
00002130.350ms: p1 leaves Q2, time in Q2 = 1.163ms
00002130.817ms: p1 begins service at S2, requesting 2857ms of service
00004991.834ms: p1 departs from S2, service time = 2861.017ms, time in system = 3945.962ms
00004992.989ms: emulation ends
Statistics:
average packet inter-arrival time = 1.04587
average packet service time = 2.86102
average number of packets in Q1 = 0.21675
average number of packets in Q2 = 0.000232927
average number of packets at S1 = 0
average number of packets at S2 = 0.573007
average time a packet spent in system = 3.94596
standard deviation for time spent in system = 0
token drop probability = 0
packet drop probability = 0
Later on, when you get your simulation working, you should run:
./warmup2 -n 1
and the order of events you get in your printout should be identical to the above (although you may get a different
server to transmit p1).
Of course, the actual timestamps may be different, but the order of events must be identical to the above because this is the only
correct order of events (and you need to figure out why)!
If you run:
./warmup2 -n 1 -r 5
you should get something like the following (again, the order of events in your printout should be identical to the following
(although you may get a different server to transmit p1)):
Emulation Parameters:
number to arrive = 1
lambda = 1
mu = 0.35
r = 5
B = 10
P = 3
00000000.000ms: emulation begins
00000200.269ms: token t1 arrives, token bucket now has 1 token
00000400.537ms: token t2 arrives, token bucket now has 2 tokens
00000600.822ms: token t3 arrives, token bucket now has 3 tokens
00000801.087ms: token t4 arrives, token bucket now has 4 tokens
00001001.069ms: p1 arrives, needs 3 tokens, inter-arrival time = 1001.069ms
00001001.094ms: p1 enters Q1
00001001.099ms: p1 leaves Q1, time in Q1 = 0.005ms, token bucket now has 1 token
00001001.110ms: p1 enters Q2
00001001.143ms: p1 leaves Q2, time in Q2 = 0.033ms
00001001.152ms: p1 begins service at S2, requesting 2857ms of service
00003861.102ms: p1 departs from S2, service time = 2859.950ms, time in system = 2860.033ms
00003861.535ms: emulation ends
Statistics:
average packet inter-arrival time = 1.00107
average packet service time = 2.85995
average number of packets in Q1 = 1.29482e-06
average number of packets in Q2 = 8.54582e-06
average number of packets at S1 = 0
average number of packets at S2 = 0.740625
average time a packet spent in system = 2.86003
standard deviation for time spent in system = 0
token drop probability = 0
packet drop probability = 0
Please note that one major difference between the above printouts is that in the first case (when "r = 1.5"), it's the token thread that moves the packet from Q1 to Q2, while in the 2nd case (when "r = 5"), it's the packet thread that moves the packet from Q1 to Q2. You need to understand why things must happen this way.
Please understand that even if you run the same command over and over again, you should get a slightly different printout every time. Also, if you run this case over and over again, about 50% of the time, p1 should be transmitted by S1 and the rest of the time, p1 should be transmitted by S2. (This probably won't happen on a 32-bit Ubuntu 16.04 system. But it can happen in some other system.) If it turns out that p1 is served by the same server in every run, it does not necessarily mean that you have a bug in your code! If that happens, you should check your code to make sure that you don't have a bug in your code that creates a condition that makes p1 to be served by the same server every time. Later on, when you have more code implemented and test with "txfile.txt in the spec", you need to make sure that in every run of your code with that input file, there would be a time when both servers are "transmitting" simultaneously.
If you don't know for sure why the above sequence of events is the right sequence of events or not sure where I got all these numbers, please feel free to send me e-mail.
You need to create 4 threads (packet thread, token thread, two server threads) and have them works together to create packets at the right times, move packets from Q1 to Q2 at the right times, and transmit packets at the right times and you need to use one mutex and one condition variable to synchronize these threads. Think of each thread as a person that works for you and think of the "serialization box" mentioned in lectures as a room that has Q1, Q2, and the token bucket in it. The room has one key and only the person who has the key can enter the work and work inside the room. Other people who do not have the key cannot know anything about what's going on inside the room. As their boss, what instructions do you give each person so that they can work together to simulation the operation of the token bucket filter mentioned in the spec perfectly?
In this case, the key is the mutex (also referred as the "lock") and it comes with a "serialization box". Your "instructions" is the first procedure of these threads. What does each thread have to do before it enters the "serialization box"? Once a thread enters the "serialization box", what must it do? The starting poinst would be the skeleton code for arrival threads and the skeleton code for server threads.
Since the Q2 buffer is infinite. The producer never has to wait to add "work" to Q2 if an eligible packet can be produced. The consumer must wait if there is nothing in the buffer (i.e., there is nothing to work on). The producer in this assignment is weird because there are two threads working together to produce packets for the consumer threads. If there are enough tokens in the token bucket when a packet arrives, the packet thread produces "work" and add it into Q2. If there are not enough tokens in the token bucket when a packet arrives, the packet goes into Q1 to wait for tokens. The token thread can also produce "work" and add "work" to Q2 if at the time a token is added to the token bucket, it can move the first packet in Q1 into Q2 if the token requirement of the first packet in Q1 can be satisfied.
#include <pthread.h> int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg); Compile and link with -pthread.This means that you need to use "-pthread" when you link (and it should be placed at the end of the command in your Makefile that creates the warmup2 executable file).
pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER;
Here, m is a mutex data structure. The assignment statement above is the way a data structure can be initialized
(i.e., initialize each field inside the data structure). So, what is PTHREAD_MUTEX_INITIALIZER exactly?
If you do the following in Ubuntu 16.04:
grep PTHREAD_MUTEX_INITIALIZER /usr/include/*.h
you would see that it's defined in /usr/include/pthread.h and it looks like (some stuff deleted):
#ifdef __PTHREAD_MUTEX_HAVE_PREV
# define PTHREAD_MUTEX_INITIALIZER \
{ { 0, 0, 0, 0, 0, __PTHREAD_SPINS, { 0, 0 } } }
#else
# define PTHREAD_MUTEX_INITIALIZER \
{ { 0, 0, 0, 0, 0, { __PTHREAD_SPINS } } }
#endif
In one case, PTHREAD_MUTEX_INITIALIZER is { { 0, 0, 0, 0, 0, __PTHREAD_SPINS, { 0, 0 } } },
and in another case, PTHREAD_MUTEX_INITIALIZER is { { 0, 0, 0, 0, 0, { __PTHREAD_SPINS } } }.
This is advanced C code and we don't need to get into it too much. What's important to understand here is the following.
- This is how to assign initial values to a data structure that has multiple fields in C. In this example, the first field of the first field gets a 0, the 2nd field of the first field gets a 0, the 3rd field of the first field gets a 0, etc.
- The mutex data structure has different number of fields in different implementations of the pthread library, i.e., sizeof(pthread_mutex_t) may get a different value in different systems! Which way is it on a 32-bit Ubuntu 16.04 system? It doesn't (and shouldn't) matter! If you want to investigate, please do it when you have nothing else to do.
for (;;) {
sleep
generate a packet/token
add a packet/token to the token bucket filter
}
The basic idea is that every time you go through the loop, one packet/token got generated and got added to the token bucket filter.
Here's a little more detail.
for (;;) {
get inter_arrival_time, tokens_needed, and service_time; /* read a line from tsfile if in trace mode */
usleep(...); /* derive sleep time from inter_arrival_time */
packet = NewPacket(tokens_needed, service_time, ...);
pthread_mutex_lock(&mutex);
Q1.enqueue(packet);
... /* other stuff */
pthread_cond_broadcast(&cv);
pthread_mutex_unlock(&mutex);
}
The blue code is inside the critical section of the arrival thread.
for (;;) {
if there are no packets in Q2, wait
remote one packet from Q2
transmit the packet
}
The basic idea is that every time you go through the loop, one packet got removed from the token bucket filter and got transmitted.
Here's a little more detail.
for (;;) {
pthread_mutex_lock(&mutex);
while (Q2.length == 0 && !time_to_quit) {
pthread_cond_wait(&cv, &mutex);
}
packet = Q2.dequeue();
pthread_mutex_unlock(&mutex);
usleep(packet.service_time);
}
The blue code is inside the critical section of the
corresponding server thread.
If a thread is executing between the pthread_mutex_lock() and pthread_mutex_unlock() calls, it is considered to be executing inside a critical section with respect to the corresponding mutex.
The call to pthread_cond_wait() above is not colored blue for the following reason. If a thread calls pthread_cond_wait() inside its critical section, the mutex is released and it is out of the critical section. When this thread receives a signal on the corresponding condition variable, the pthreads library will lock the mutex on its behalf and put it back inside the critical section before pthread_cond_wait() returns. To be more correct, the call to pthread_cond_wait() should be colored partially blue.
Pthreads guarantees that only one thread can be executing in a critical section with respect to the same mutex. So, if the arrival thread is executing inside its critical section, you can deduce that none of the service threads are executing in their critical sections.
If you implemented your guarded command correctly (and if you have a guard, always re-evaluate the guard whenever you return from pthread_mutex_lock() or return from pthread_cond_wait()), then it is always "correct" to broadcast the CV! In some cases, signaling the CV may be more "efficient". But for this assignment, always broadcast the CV would be fine. For this assignment, it's more important that your code works correctly (even though it may not be super efficient). The spec requires you to always broadcast a CV and never signal a CV. So, please follow the spec.
The interesting case is that you write a function, say f(), and it's not meant to be recursive and somehow when you are executing code inside f(), f() gets called again before you left f() the first time. Now we have to worry if you have written f() to be reentrant or not.
So, how can this happen? Clearly, if you have multithreading, thread 1 can call f() and white thread 1 is executing code in f(), thread 2 also calls f() before thread 1 has returned from f(). If you write f() correctly, this would be okay. As mentioned in lecture, we say that f() is "thread-safe" because we are talking about multithreading.
What if you don't have multiple threads? It's possible that if you have a signal handler that calls f(), then f() can be entered twice. For example, if you are executing code in f() and your thread is borrowed to deliver a signal before you return from f(). Inside the signal handler, if you call f() and now you would enter f() twice (without leaving).
If you look at the Wikipedia page about reentrancy and look at the examples for bad code, they all involved using global variables to store temporary values. So, the take away is that you should not use global variables to store temporary values! Also, as mentioned in lecture and above, signal handlers are bad news and you should catch SIGINT using a SIGINT-catching thread and not use signal handlers!
Finally, if you don't have signal handlers and only have threads, can you use global variables? Absolutely! You just need to make sure that you only access shared things with critical section code! Since we are only using one mutex, all the critical section code will be with respect to the same mutex!
gcc -pthread -o warmup2 -g -lm warmup2.o my402list.o
You would get "undefined references" because the order of libraries and .o files matter.
The libraries need to go at the end, after all the .o files. So, you should do:
gcc -g -Wall -o warmup2 warmup2.o my402list.o -pthread -lm
What happens is the when the linker (see Ch 3) performs "symbol resolution", it would only "look to the right" in the commandline to resolve symbols.
So, if you call pthread_create() in "warmup2.o", "-pthread" needs to be to the right of "warmup2.o" in the commandline.
-D_POSIX_C_SOURCE=199506L
You really don't need to call things like flockfile().
You just need to make sure that you call printf() when you have the mutex locked.
If you are not familiar with all these, please review the lecture on waiting and signaling condition variables from Ch 2 of the textbook.
But be careful about exactly what it means to "signal" something because there are two types of signals! They are UNIX signals and pthread events (where you can signal an event). You must read the man pages carefully and see which type of signal can be used to unblock something.
For example, if you are blocked because you call pthread_cond_wait(), your thread will not be woken up if you send a UNIX signal to it. Why? Because if you read the man pages of pthread_cond_wait(), it doesn't say anything about UNIX signals!
This seems expensive in terms of extra delays, but it's perfectly fine for an assignment like this. Although you need to be careful and not have too many tiny critical sections in your thread.
Let's say that your print at time equal to 1 second that p1 begins service and requesting 2 seconds of service. When you wake up, it's 2.01 seconds later instead of 2 seconds later. Let's say that it takes you another 0.01 seconds to lock the mutex. Must you print that the service time is 2.01 seconds? Or, would it be fine to CLAIM that your service time is 2.02 seconds instead? How does the user know that you didn't wake up 2.02 seconds after you sleep and takes no time to lock the mutex?
The point I'm trying to make is that you, the programmer, decide when you CLAIM that a packet has finished service. If you know that printing it as soon as the packet finished service, your timestamps may be out of order, and if you print it after you have the mutex locked, your timestamps will be in order, since the user cannot tell exactly when a packet finished service, you should CHOOSE to implement it so that the printout always looks right.
The spec says that, for every packet, you have to print these events in the printout (using packet #1 as an example):
(1) p1 arrives, needs 3 tokens, inter-arrival time = 503.112ms
(2) p1 enters Q1
(3) p1 leaves Q1, time in Q1 = 247.810ms, token bucket now has 0 token
(4) p1 enters Q2
(5) p1 leaves Q2, time in Q2 = 0.216ms
(6) p1 begins service at S1, requesting 2850ms of service
(7) p1 departs from S1, service time = 2859.911ms, time in system = 3109.731ms
Let's take a look at line (1).
What does "p1 arrives" really mean? Well, the spec doesn't say exactly what this means!
You get to decide when you would claim to be the exact instance of time p1 arrives!
When must you call gettimeoutday() to get the clock value for this event?
Must you read the clock when your packet arrival thread returns from usleep()? The answer is no.
(If you think the answer is yes, you need to pin-point the exact place the spec says so.)
Must you read the clock when your packet arrival thread returns from malloc() to "create the packet"? No.
Can you read the clock after your packet arrival thread has returned from pthread_mutex_lock() so you can be
100% sure that no other thread will call gettimeoutday() at the same time and mess up the timestamp sequence? Yes!
What if after you have read the clock to get the clock value for (1) and you release the mutex and lock the mutex when you are ready to print line (1)?
Not a good idea! If you do that, your timestamps may be out of order and the user will say that you have a bug in your simulation
because your timestamps are out of order! So, reading the clock and printing the printout related to that timestamp must be done in one atomic operation!
Should it takes 10 extra milliseconds then? I don't know because I don't know if there are bugs in your code. You need to determine if this is reasonable! You should write a small bug-free program to see what's a reasonable overhead on Ubuntu on your machine.
When you implement your assignment, do not anticipate exactly how fast or slow your system will respond. If your Ubuntu system got an upgrade and became super fast, you must not need to change your code in order for your program to run correctly. Also, you don't know what type of machine the grader has and you cannot predict the overhead on the grader's Ubuntu system.
void SleepTillTime(Y)
{
gettimeofday(&now, NULL);
while (now < Y) {
usleep(Y-now);
gettimeofday(&now, NULL);
}
}
Since the above is pseudo-code, please don't be surprised if the time units are all wrong.
Please also note that the above code doesn't care about the return value of usleep()!
Some students would prefer to use nanosleep() and that would be fine. But it's really not necessary because we are not running a realtime OS.
For a server (S1 or S2), we need to simulate the transmission of a packet and the transmission of a packet takes time. In that case, we call usleep() to sleep for the packet transmission time.
For the packet arrival thread, when it's finished interacting with other threads (i.e., updating the shared data structures), it has nothing to do but to wait for the right time to generate the next packet. In that case, the packet arrival thread should call usleep() to sleep for the right amount of time so that when it wakes up (i.e., returns from usleep()), it will be the time when the next packet is supposed to arrive.
For the token depositing thread, when it's finished interacting with other threads, it has nothing to do but to wait for the right time to generate the next token. In that case, the token depositing thread should call usleep() to sleep for the right amount of time so that when it wakes up, it will be the time when the next token is supposed to arrive.
In all the above cases, you must call usleep() when you don't have the mutex locked.
Let's say that you have something that looks like the skeleton code for the arrival thread. Furthermore, in the SIGINT handler, you set a global variable to inform all your threads that <Ctrl+C> has been pressed and all threads should start the self-termination process. Then you should check this global variable just before and just after the usleep() call. But what would happen if <Ctrl+C> is pressed just between checking this global variable and usleep()? You will still go into usleep(). If you just happen to sleep for a long period of time, your program would behave as if it missed the <Ctrl+C> when the <Ctrl+C> was pressed.
What's the cause of the race condition? It's the same problem as the "Waiting for a Signal" problem mentioned in the slides on "deviations" (section 2.2.5 of textbook). The solution is to first block the signal. Then when the thread is ready, unblock the signal AND wait for the signal using an atomic operation!
One solution is to use pthread_kill() in the signal handler to send a signal (e.g., SIGUSR1) to the arrival thread (after it has set the global variable). Then in the arrival thread, block SIGUSR1, check global variable, then unblock SIGUSR1 and wait for SIGUSR1 and sleep in one atomic operation with sigtimedwait(). This sounds complicated and error prone because it is!
I do not recommand that you use pthread_kill(). I also do not recommand that you use signal handlers! The best way to go is to use a SIGINT-catching thread and call sigwait() in it. As I have explained in lectures, the best way is not to ever use a signal handler! Using sigwait() to handle signals synchronously is the best way to go! Make sure you block all signals in all your threads. Please also use the pthread cancellation mechanism to terminate the packet arrival and the token depositing threads when <Ctrl+C> is pressed. Please review relevant lectures in Ch 2.
If your threads are doing something useful (i.e., simulating) and using up all the CPU, it's perfectly fine to and that would not be busy-waiting!
If you suspect that your code is doing busy-waiting, you can profile your program and see if you are calling some functions unusually too many times and that may give you a hint about whether you are doing busy-waiting or not.
00000501.031ms: token t2 arrives, token bucket now has 2 tokens
You can do:
printf("%08d.%03dms: token t%d arrives, token bucket now has %d tokens\n", 501, 31, 2, 2);
Of course, all the numbers above came from your simulation.
In general, "%d" means to print the corresponding integer value here. If you add "0n" before it (where n in a number), it means to print the value within exactly n spaces and pad it with leading zeroes.
For this assignment, if you press <Ctrl+C>, a signal is delivered to your application and you are supposed to handle it and not let your program die! The spec says that if a server thread is transmitting a packet, you must let it finish. Therefore, <Ctrl+C> does not mean that you are done with the simulation.
What you are supposed to do when SIGINT is delivered is that you must gracefully shutdown your simulaiton. When you print the "SIGINT caught" line in the printout, that's part of your simulation (and therefore, you must print it in a line with a timestamp). You need to let your simulation finish, but you need to make sure that once you have printed the "SIGINT caught" line in the printout, the packet thread must not generate another packet, the token thread must not generate another token, and the server threads must not transmit a new packet. You also need to let your simulation finish before you can print statistics, i.e., wait for your main thread to join with all 4 threads, you can delete all the "removed packets" afterwards (but remember that deleting a "removed packet" is a simulation event and you must print it in a line with a timestamp). After all 4 threads are dead and all the "removed packets" have been deleted, you can then print the "emulation ends" line (and it must also have a timestamp). Only after that, you print statistics.
When the grader grades, the grader will not use this script if <Ctrl+C> is to be pressed!
handle SIGINT pass
Let's do some simple calculation (not exactly our simulation). The default values are lambda = 1, mu = 0.35, r = 1.5, and P = 3. This means that the service time is 1/0.35 = 2.857 seconds. Since r = 1.5, a token will arrive about 0.667 seconds. Since P is 3, it will take 2 seconds for 3 token to arrive. Therefore, p1 will enter one of the servers a little after 2 seconds into the simulation. This packet should leave the system around 4.867 seconds into the simulation. p2 should arrive around 2 seconds into the simulation but it won't have enough tokens. A little past 4 seconds into the simulation, token t6 has arrived and now p2 should be moved into Q2 and ready for transmission. Since the first server is busy transmitting p1, you must make sure that the other server will start transmitting p2 at this time or you have a bug in your code.
Draw a timing diagram and convince yourself that what I said above is the correct expected behavior. Then find out where your bug is.
Well, when you run your code in the trace-driven mode, your program can only handle one type of input file and that's a tsfile. Therefore, your program must assume that the given input file is a tsfile! What if it turns out that it's not? Then the user has made a mistake and you must give up (i.e., print an error message and quit your program) as soon as you have realized that it's not a valid tsfile. What if you are already started your simulation and has already printed out a bunch of stuff on the screen? You should do exactly the same thing, i.e., print an error message and quit your program immediately. There is absolutely no requirement that you have to recover from this type of error if the user gave you an invalid file to process! It's not your responsibility to handle an input file that does not conform to the tsfile specificiation. But it's your responsibility to print an error message and quit your program immediately when you see that the input file is not a conforming tsfile.
One more thing, in the trace-driven mode, you must NOT validate the entire tsfile before you start your simulation! You must assume that the entire tsfile is valid and proceed with your simulaiton. If it turns out that the tsfile is bad (clearly, not your fault), you must print an error message and quit your program immediately when you see that the input file is not a conforming tsfile. Why must you do it this way? Well, because validating your input file is not a requirement! What if the tsfile has 1 billion lines? If you spend a lot of time validating your input file and delay the start of your simulation, it would be wrong to do so.
If you are familiar with strtok(), then it's great! If you are not familiar with strtok(), then you need to read the man pages very carefully to understand how it works. One common mistake is to use strtok() in a nested loop! Make sure you never do that!
Another way is to use sscanf() to get integers from a line. For example, if you do:
int a=0, b=0, c=0;
if (sscanf(buf, "%d %d %d", &a, &b, &c) == 3) {
/* got 3 integers in a, b, and c */
}
If you have never used sscanf() before, write a tiny program to test out your code
and try a bunch of cases (such as using arbitrary number of space and tabs between these intergers and see what happens)
until you are comfortable with using it. For example (please understand what each and every line of code is doing):
#include <stdio.h>
int main(int argc, char *argv[])
{
printf("> ");
char buf[80];
if (fgets(buf, sizeof(buf), stdin) != NULL) {
int a=0, b=0, c=0;
if (sscanf(buf, "%d %d %d", &a, &b, &c) == 3) {
printf("a = %1d, b = %1d, c = %1d\n", a, b, c);
} else {
printf("Input does not contain 3 integers!\n");
}
}
return 0;
}
If you are running in the trace-driven mode, you should read the first line of the tsfile before you start your simulation and set n to be the value in the first line. Then in the code of the packet arrival thread, whenever you are ready to sleep to wait for a packet to arrive, if you are running in the trace-driven mode, you should read the next line from the tsfile, parse that line and store the results in local variables and then sleep for the right amount. When the packet arrival thread wakes up, you should then create a packet object (using malloc()) and put all these information into the packet object. What if you are running in the deterministic mode? Well, you already have all the information you need for every packet.
Basically, everything after the "emulation begins" line should all be measured values.
For example, if the total simulation time is 9 seconds and out of the 9 seconds, Q1 has 0 packet for 2 seconds, 1 packet for 2.8 seconds, 2 packets for 2.5 seconds, and 3 packets for 1.7 seconds. The average number of packets is (0*2 + 1*2.8 + 2*2.5 + 3*1.7) / 9 = 1.433333.
So, if you can keep track of the amount of the time intervals for various queue lengths you can compute this. But this may end up with too many variables to keep track of and can get very messy. If you think about it carefully, there is actually a way to use a constant number of cumulative values to compute the same thing.
Take a look at the picture below (from a discussion section slide) that depicts the number of packets in Q1 over time:
The avarage number of packets in Q1 is the area under the curve divided by the total emulation time. One way to calculation the area under the curve is to slice up the area into vertical bars and use the method mention above to add up the amount of time Q1 has a certain number of packets. This may get a little messy to keep track. Another way to calculate the area under the curve is to look at the above picture and realize that it's the same as adding up the time spent by all the packets in Q1 (you need to look at the above picture carefully to see that this is correct)! Therefore, all you have to do is to add up all the time spent by all the packets in Q1 and you have the area under the curve! (For this assignment, one complication is that you must only consider "completed packets" for this statistics.)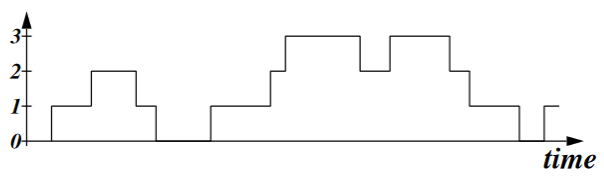
If you don't know exactly what "6 significant digits" mean, please google the term "significant digits". For our assignment, it's okay not to show trailing zeroes. For example, 1.2 should be displayed as 1.20000. But it's okay to show it as 1.2 since trailing zeroes is implied. But 0.0000123456 must not be displayed as 0.000012 since it would mean that the actual value is 0.0000120000.
oldsum = n × avg
Then the new sum must be oldsum plus s and the new avg must be:
avg = (n × avg + s) / (n + 1)
Therefore, to keep a running average, you need two state variables: (n,avg). When you get a new sample s, you must
update your state variables by doing:
avg = (n × avg + s) / (n + 1)
n = n + 1
Var(X) = E(X2) - [E(X)]2To keep a running average of Var(X), you just need to keep a running average of X and X2 using the method above. When it's time to report the standard deviation, you can calculate Var(X) and return the square root of it.
If you only have one packet and if you do that math, the variance must be equal to exactly 0. Although when you write it in code, you may notice that the variance may end up to be a very very small negative number. If you take square root of a negative number, you will end up with an invalid value (i.e., NaN). The spec says that you must never print NaN.
It's important to understand how floating point numbers are represented in a programming language (such as C). A floating point number has "finite precision", i.e., not all floating point numbers can be represented. So, depending on how you calculate something, you might get a slightly different value (due to truncation). Therefore, two formula that's supposed to get exactly the same real value may end up to be slightly different and if you subtract one from another, you may end up with a small negative value.
To get around this issue, what I would do is that before you take square root of a real value, check to see if the absolute value of the value you are taking square root is very very small. If it's very very small, you can just treat it as zero! What is very very small? How about 10^(-8), i.e., (1.0E-8)?!